

If you operate AI systems long enough, you eventually discover the quiet constraint that governs everything: tokens.
They rarely appear in product demos. They are barely mentioned in marketing material. Yet tokens determine cost, latency, system limits, and operational reliability for every modern AI platform.
Tokens are not just a billing detail. They are the fundamental resource that language models consume — and the most important invisible constraint in any AI-powered system.
Most teams discover them accidentally. An application suddenly becomes expensive. Response times begin drifting upward. A workflow that worked during testing begins failing under real usage. Prompts start truncating important context.
Underneath those symptoms sits the same mechanism counting every piece of text that flows through the model. Tokens are not just a billing detail. They are the fundamental resource that language models consume.
For anyone working in AIOps, SRE, or platform engineering, token management belongs in the same category as CPU, memory, and network capacity. Ignore it and the system eventually pushes back.
What a Token Actually Is
Language models do not process words the way humans read them. Before any prompt reaches the model, the text is broken apart by a tokenizer into smaller units called tokens.
Sometimes a token represents an entire word. Sometimes it represents a fragment of a word, punctuation, numbers, or formatting characters. The tokenizer converts those pieces into numeric IDs that the model can process.
This detail matters because tokens are the unit that defines every operational limit in the system. Every model has a maximum context window measured in tokens. Every request is priced by tokens. Every response is generated token by token.
When you send a request to an AI model, two things immediately begin happening behind the scenes. First the entire prompt is converted into tokens and counted. Then the model begins generating output tokens one at a time until it completes the response or reaches its output limit. The meter is running the entire time.
The Two Token Flows in Every AI Request
Every AI interaction contains two streams of tokens moving through the system.
The first stream comes from the input context. Everything included in the prompt becomes part of the model’s working memory for that request. System instructions, prior conversation history, retrieved documents, tool outputs, schemas, and even formatting rules are all part of that context. In modern production systems this context grows quickly — it is common for a single request to contain several thousand tokens before the model even begins generating an answer.
The second stream comes from the model’s response. The output is also produced token by token. A short answer may only generate a few hundred tokens, while long analysis or generated documents can easily run into the thousands. Most teams underestimate the output side. Long-form responses, summaries, incident reports, or generated documentation frequently consume more tokens than the input prompt itself.
Where Token Usage Starts Affecting Reliability
Once AI systems move beyond experimentation and into production, token behavior begins influencing system stability in several ways.
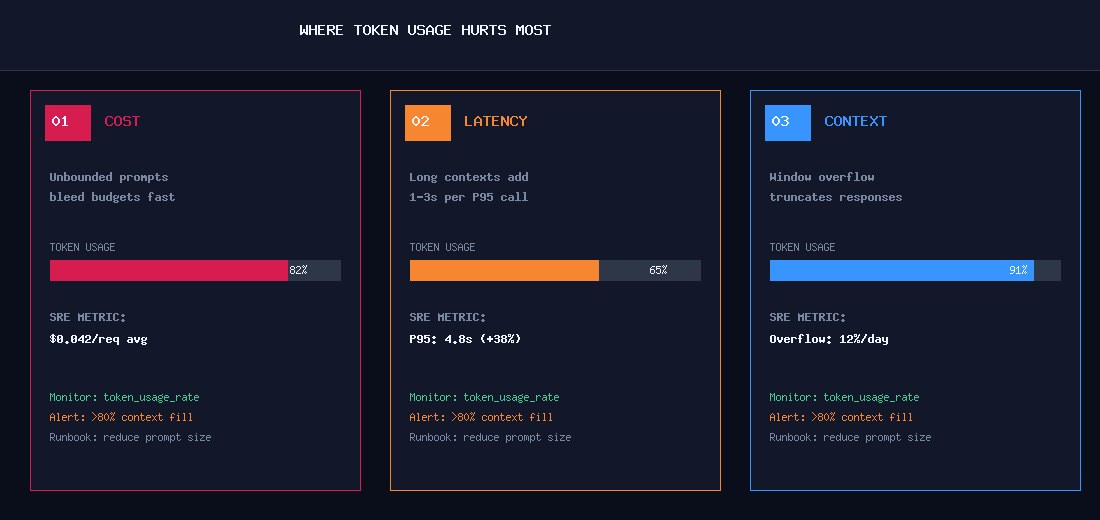
The first pressure point is cost. Every token processed by a hosted model carries a price. A prompt that is twice as long is literally twice as expensive to process. At production scale this becomes significant infrastructure spend.
The second pressure point is latency. Language models must evaluate the entire prompt before they begin generating output. A prompt containing several thousand tokens requires more computation than a short one — and large outputs extend the response time even further.
The third pressure point is context limits. Every model has a maximum context window. Once the combined size of input and output tokens reaches that limit, earlier context disappears or the request fails. Systems that continuously append logs, documents, or conversation history eventually hit this boundary.
When teams begin building AI assistants, operational copilots, or incident analysis systems, these three constraints surface quickly. The system does not break in obvious ways. Instead it becomes SLOwer, more expensive, and occasionally blind to important context.
Tokens in Real AIOps Workflows
For teams building operational AI systems, token usage appears in places that are not obvious at first.
Incident analysis systems often attach logs, metrics summaries, Runbooks, and event timelines into a prompt. Those artifacts can easily consume thousands of tokens. If the system also includes historical incident comparisons or architectural context, the prompt size grows rapidly.
Chat-based operational assistants encounter a different issue. Each turn in the conversation adds more tokens to the context window. Without careful pruning or summarization, long operational threads eventually push earlier context out of memory.
Retrieval augmented generation introduces another layer. When a search component retrieves documentation or past incident records, the system may inject multiple documents into the prompt. Those documents become tokens whether the model uses them or not. In each case the model behaves correctly — it simply operates within the limits of its token budget.
Why Reliability Engineers Need to Track Token Consumption
Traditional reliability engineering focuses on resource visibility. Engineers track CPU usage, memory pressure, network saturation, and storage growth because those signals reveal when systems approach operational limits. AI systems require the same discipline, but the critical resource is different.
Token consumption becomes the operational signal that tells you how the system is behaving. Large prompts reveal architectural inefficiencies. Sudden spikes in token usage often indicate runaway agent loops or poorly scoped retrieval queries. High output token counts frequently point to prompt instructions that encourage unnecessary verbosity.
Teams that instrument token usage gain visibility into how their AI systems actually behave in production. Once that visibility exists, optimization becomes straightforward. Prompts can be shortened. Retrieval pipelines can filter irrelevant documents. Agents can summarize previous context instead of passing entire conversations forward. What begins as cost optimization quickly becomes reliability engineering.
Designing Systems That Respect the Token Budget
The most reliable AI systems treat tokens as a limited resource rather than an infinite stream. That mindset changes architectural decisions. Instead of dumping entire documents into prompts, systems retrieve only the most relevant sections. Instead of carrying full conversation history forever, they periodically summarize prior context into shorter representations.
Operational assistants often perform best when the prompt remains small and structured. The model receives exactly the information it needs to reason about the problem rather than a flood of loosely related context. These patterns resemble traditional system design — efficient systems minimize unnecessary data movement and avoid expensive operations whenever possible. Token-aware AI systems follow the same philosophy.
The Quiet Constraint Behind AI Reliability
Large language models feel magical during the first few experiments. They accept huge prompts, produce long responses, and appear to reason over enormous bodies of text. But underneath that experience sits a very simple accounting system.
Every character becomes tokens. Every token consumes compute. Every request operates within a fixed window.
Once you understand that constraint, many behaviors that once seemed mysterious become predictable. Systems slow down because prompts grew too large. Costs climb because workflows generate unnecessary tokens. Context disappears because the system exceeded the window.
Reliability engineering has always been about understanding the invisible limits that shape system behavior. In the world of AI, the most important one is counted one token at a time.
Continue Reading
🤖The practitioner guide to AIOps: alert correlation, anomaly detection, LLM integration, and automated remediation.
Metrics, distributed tracing, structured logs, SLOs, and Error Budgets — and how to extend them for AI systems.
Stay Sharp
New articles on AIOps and SRE, straight to your inbox.
Practical content for practitioners. No noise, no vendor pitches.
No spam. Unsubscribe any time.